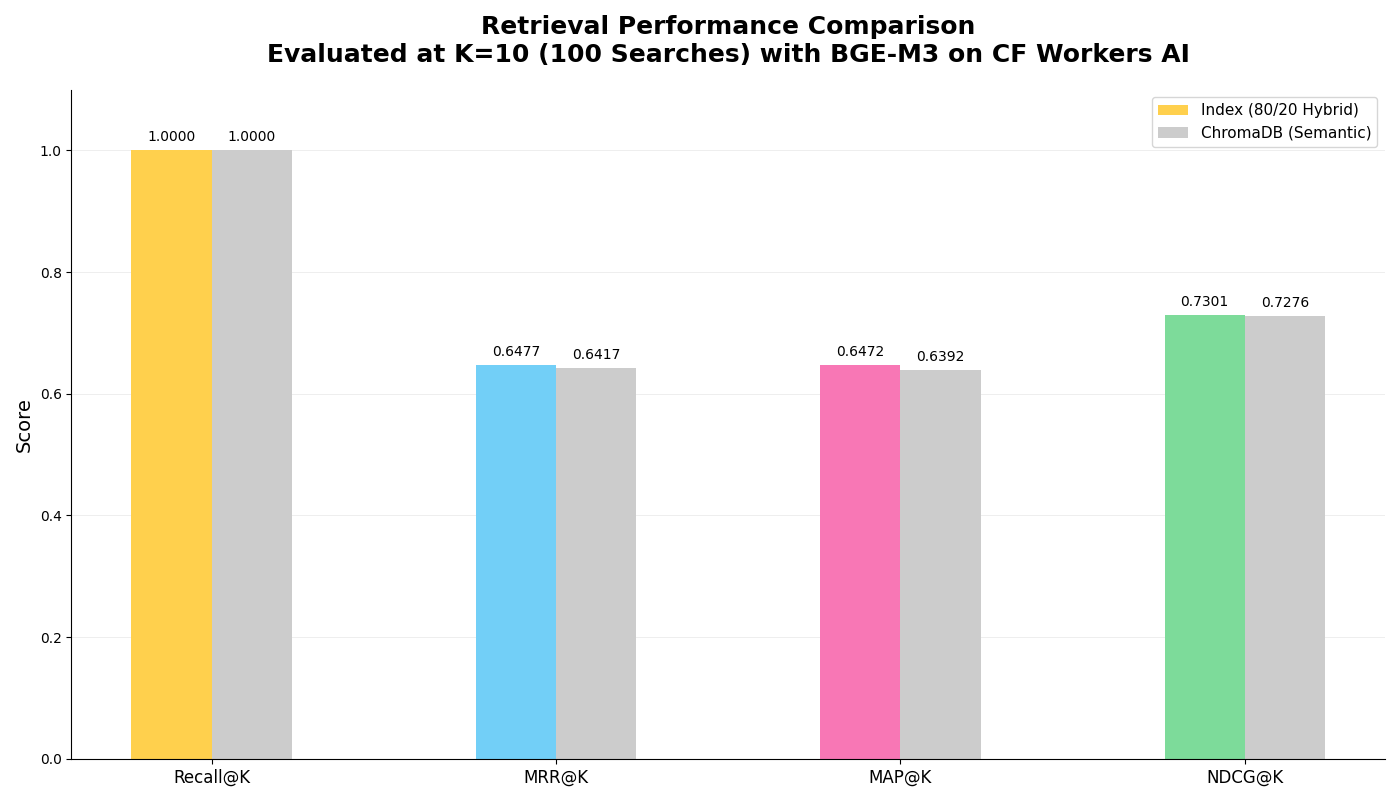
This work is currently in progress. Please check back later for the final version.
Really Good Search is Really Hard.
A current work in progress, in San Francisco.
At Opennote, we built a low-latency search engine that allows us to retrieve multi-tenant queries in milliseconds.
In short, this is a setup with two layers, starting with a serverless set of bindings on Workers, in front of a pgvector configuration. In telling people that we decided on postgres instead of a dedicated vector database, it can raise a question.
This blog post dives into an attempt to answer exactly that decision for the infrastructure powering the knowledge layer of Opennote.
Background
A big media "trend" recently has been Personal Superintelligence. The idea revolves around the fact that AI will change the way we interact with our daily lives, becoming a personal partner in every facet of what we do. Science fiction aside, this makes reasonable sense. There are plenty of companies attempting this today (see Interaction Co, Cluely, etc.). At Opennote, we make software that allows users to think differently, and learn differently. To do this, our AI systems need to know the user.
Imagine you've just stumbled upon Opennote for the first time. You're curious what is possible. You click on the Google Drive Integration in our onboarding steps, and instantly our systems are able to build you a summary of all your class notes, or highlight key concepts, or find that tax return you were missing, all within seconds.
search("What did I learn in math class last week?")
> "You learned about the Pythagorean theorem and how to solve for the hypotenuse of a right triangle. Let's dive deeper into that."
This is that kind of magic moment that we're leading up to every time the user is on the platform. The goal is proactively understanding a user's intent, and providing them with the best results from what they've done before, platform-agnostic.
But, there's a catch. Opennote is a multitenant and collaborative tool. This means that all of our search results have to be seperated in scope, and yet, support the capability to seach across tenants simulatenously. If a user is working with a team, they want results from both the team and user's knowledge. If a user is working between the web and their work, they want both results at the same time.
Lastly, our search isn't like code or a traditional setup like Google Search. We can't build a graph from text chunks, as paragraphs lack the consistent structure that code blocks have. Unlike, for example, Cursor's codebase indexing, writing is open-ended and highly variable. And finally, there's no way to rank results based on popularity, because the primary searcher is not the user, but rather an agent, that can search for many different things across many different contexts.
How does AI understand?
To understand how we can best structure a corpus for AI to understand, we need to understand how AI understands. Search agents don't search like human beings. Humans build a mental model of the place they search within rather than being directional. Humans know where to look, what to search for, and the limitations of a system and search space as they use it. AI is not that smart. Models rather calculate a trajectory, searching for a variety of keywords and context to determine what the user is looking for. Models also have a tendency to hallucinate, get lost, or return results they may deem accurate as they have no mental model or memory of the corpus they are working within. This may work for less complex systems, or for corpora that have millions of documents where a difference of a few words is inconsequential.
For Opennote's search, however, we can't rely both on the user to have the right information, nor on the model to have the right memory or trajectory. We are required to build a system that can return the most accurate result (or set of results) regardless of the scale of the search. And lastly, we're building a consumer-facing application, so latency is a major factor. Unlike deep research tasks that have the liberty to take minutes, we only have milliseconds to make sure we get a result and proceed. Somewhat a hard problem indeed.
Searching (ba-dum-tss) for a solution
So now, we've defined a problem. How does one go about solving it? This is where one might search for a product that just solves this problem immediately for us and call it a day. But this problem seemed so interesting to me that I started to dive into research.
A traditional vector retrieval system is what many queries lead to. Most of these follow the same schema, of a user-defined id, embedding, metadata, and a search function that returns the top $k$ results. This is a great starting point and where we initially began with our existing search system. We had collections per user which allowed for seperation of scopes, with IDs linking back to documents alongside the text that was embedded.
This worked. However, it was the furthest thing from fast. Hybrid search required searching for $n$ documents semantically, then $m$ documents through a slower full-text or regex based search, and returning a reranked mix. Metadata filtering was not built as a end-all solution, and didn't offer the scale we needed. And the largest issue (beyond mentions of search speed being sometimes over 10 seconds) was absolutely no support for multi-tenant search.
The second line in the pgvector README states "Store your vectors with the rest of your data."
This started to make a lot of sense. We need rich and full featured text search that Postgres also supports, alongside an ability to search for meanings, both to stretch our use case beyond repeating text from documents from full-text matching, and for making sure that AI was well integrated into the loop.
The last question before I could dive into implementation was speed. Supabase seemed like a no-brainer for storage due to the full-featured Postgres capabilities, but what about for implementation? This is where taking a shot in the dark with Workers paid off. By bringing the API and AI infrastructure right near a user, we were already at the stage of milliseconds required to search. With that, all the ingredients are gathered for "hopefully" good search.
Prototyping -1 to 0
The first version of Index was built on the following layout. Any format of document, including Journals through the Opennote API are serialized to markdown with associated metadata of the entity that owns it (a user, a team, or a more "public" entity, such as "web"Having a "web" entity means that we can search across user documents and cached web results simultaneously, which ends up being a pretty nice way of solving parallel search using the multi-tenancy itself.).
That document is then chunked recursively into sections. We chose this strategy as it provides the lightest weight option for our use case (prioritizing speed) while retaining a good amount of meaning, and being somewhat standard for RAG applications. Once a document is chunked, we then generate a full text summary that highlights the main overview of the document. This step is not meant for the accuracy of search, but rather for the model once it recieves top results, to build a better picture for the final response.
Lastly, we follow pretty standard steps for indexing. All chunks are embedded and inserted into the database, which is distributed across partitions based on each entity. This helps our indexes be faster and filter our search across the relevant entities and partitions rather than the entire database.